- INFORMATION (THÉORIE DE L’)
- INFORMATION (THÉORIE DE L’)La théorie de l’information ou, de façon plus précise, la théorie statistique de la communication, est l’aboutissement des travaux d’un grand nombre de chercheurs (H. Nyquist, R.W.L. Hartley, D. Gabor...) sur l’utilisation optimale des moyens de transmission de l’information (téléphone, télégraphe, télévision, etc.). Le premier exposé synthétique de cette théorie est dû à Claude E. Shannon, ingénieur aux Bell Telephone Laboratories. L’idée fondamentale est que l’information doit être transmise à l’aide d’un canal (ligne téléphonique, ondes hertziennes). On est alors conduit à étudier d’une part l’information proprement dite (quantité d’information, entropie d’une source d’information, etc.), d’autre part les propriétés des canaux (équivoque, transinformation, capacité, etc.), et enfin les relations qui existent entre l’information à transmettre et le canal employé en vue d’une utilisation optimale de celui-ci.On peut ainsi considérer la théorie de l’information comme une théorie du signal au sens large. Elle intervient chaque fois qu’un signal est envoyé et reçu, et s’applique, par conséquent, aussi bien à la téléphonie, à la télégraphie et au radar qu’à la physiologie du système nerveux ou à la linguistique, où la notion de canal se retrouve dans la chaîne formée par l’organe de phonation, les ondes sonores et l’organe auditif.En fait, les concepts de base de la théorie de l’information sont d’une telle simplicité et d’une telle généralité qu’il est possible de les introduire dans n’importe quelle discipline, des mathématiques à la sociologie, mais il faut ajouter que les tentatives faites en ce sens n’ont que rarement apporté les progrès que l’on en attendait.1. Information et quantité d’informationUne information désigne, par définition, un ou plusieurs événements parmi un ensemble fini d’événements possibles. Si, cherchant un document dans une pile de dossiers, l’on dit que ce document se trouve dans un dossier rouge, on donne une information qui réduira d’autant plus le temps de recherches que le nombre de dossiers rouges est plus restreint. Si on ajoute que le document est dans un petit dossier, on fournit une nouvelle information qui abrège encore le temps de recherches.Sur un plan purement pratique, une information étant d’autant plus intéressante qu’elle diminue davantage le nombre de possibilités ultérieures, on a été conduit à définir la quantité d’information comme une fonction croissante de N/n où N est le nombre d’événements possibles et n le sous-ensemble désigné par l’information. Pour conférer à la quantité d’information les propriétés des grandeurs mesurables (définition de l’égalité et du sens de l’inégalité et définition de l’addition), on a posé par définition:
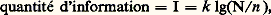 où k est une constante qui dépend du choix de l’unité. En prenant comme unité de quantité d’information (encore appelée «logon») celle qui réduit l’incertitude de moitié (n = N/2), on a k = 1/lg 2. Pour simplifier les formules, il est commode d’utiliser les logarithmes de base 2, ce qui donne finalement:
où k est une constante qui dépend du choix de l’unité. En prenant comme unité de quantité d’information (encore appelée «logon») celle qui réduit l’incertitude de moitié (n = N/2), on a k = 1/lg 2. Pour simplifier les formules, il est commode d’utiliser les logarithmes de base 2, ce qui donne finalement: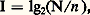 où I est exprimé en logons.Lorsqu’on dispose de deux informations, la quantité d’information totale n’est pas nécessairement égale à la somme des quantités d’information, comme on peut le voir sur l’exemple cité ci-dessus de la recherche d’un document dans une pile de dossiers.Soit N le nombre total de dossiers, n 1 le nombre de dossiers rouges, n 2 le nombre de dossiers petits et n le nombre de dossiers petits et rouges; indiquer que le document cherché se trouve dans un dossier rouge donne lg(N/n 1) logons; indiquer que le document se trouve dans un petit dossier donne lg(N/n 2) logons; enfin, l’indication que le document se trouve dans un petit dossier rouge donne log(N/n ) logons. Pour faire intervenir les informations partielles dans l’information totale, on écrira:
où I est exprimé en logons.Lorsqu’on dispose de deux informations, la quantité d’information totale n’est pas nécessairement égale à la somme des quantités d’information, comme on peut le voir sur l’exemple cité ci-dessus de la recherche d’un document dans une pile de dossiers.Soit N le nombre total de dossiers, n 1 le nombre de dossiers rouges, n 2 le nombre de dossiers petits et n le nombre de dossiers petits et rouges; indiquer que le document cherché se trouve dans un dossier rouge donne lg(N/n 1) logons; indiquer que le document se trouve dans un petit dossier donne lg(N/n 2) logons; enfin, l’indication que le document se trouve dans un petit dossier rouge donne log(N/n ) logons. Pour faire intervenir les informations partielles dans l’information totale, on écrira: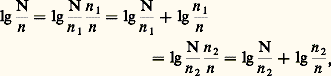 où lg(n 1/n ) est la quantité d’information supplémentaire que donne l’indication «dans un dossier petit» lorsque l’indication «dans un dossier rouge» est déjà connue.Ainsi, si l’on a 800 dossiers dont 200 petits, 50 rouges et 20 qui soient à la fois rouges et petits, l’information «dans un dossier rouge» vaut lg(800/50) = 4 logons, l’information «dans un dossier petit» vaut lg(800/200) = 2 logons et l’information «dans un petit dossier rouge» vaut lg(800/20) = 5,32 logons, et non 6 logons.Pour prendre un autre exemple, on peut rechercher quelle est la quantité d’information contenue dans le discours d’une personne disposant de 4 000 mots et parlant pendant dix minutes. Si l’on admet que la vitesse d’élocution est de 3 mots par seconde, le discours comportera 1 800 mots; le nombre maximal de discours possibles étant égal au nombre de combinaisons de 4 000 mots pris 1 800 par 1 800, on aura:
où lg(n 1/n ) est la quantité d’information supplémentaire que donne l’indication «dans un dossier petit» lorsque l’indication «dans un dossier rouge» est déjà connue.Ainsi, si l’on a 800 dossiers dont 200 petits, 50 rouges et 20 qui soient à la fois rouges et petits, l’information «dans un dossier rouge» vaut lg(800/50) = 4 logons, l’information «dans un dossier petit» vaut lg(800/200) = 2 logons et l’information «dans un petit dossier rouge» vaut lg(800/20) = 5,32 logons, et non 6 logons.Pour prendre un autre exemple, on peut rechercher quelle est la quantité d’information contenue dans le discours d’une personne disposant de 4 000 mots et parlant pendant dix minutes. Si l’on admet que la vitesse d’élocution est de 3 mots par seconde, le discours comportera 1 800 mots; le nombre maximal de discours possibles étant égal au nombre de combinaisons de 4 000 mots pris 1 800 par 1 800, on aura: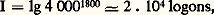 et cela quels que soient le discours et son contenu, même s’il est complètement incohérent. On voit dans ce cas à quel point la notion mathématique d’information est différente de l’information au sens usuel.2. Entropie d’une partitionConsidérons un ensemble E et soit E1, E2, ..., En des sous-ensembles formant une partition de E. La quantité d’information liée à Ei est par définition:
et cela quels que soient le discours et son contenu, même s’il est complètement incohérent. On voit dans ce cas à quel point la notion mathématique d’information est différente de l’information au sens usuel.2. Entropie d’une partitionConsidérons un ensemble E et soit E1, E2, ..., En des sous-ensembles formant une partition de E. La quantité d’information liée à Ei est par définition: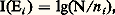 et l’entropie de la partition est définie par:
et l’entropie de la partition est définie par: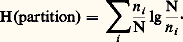 Cette notion assez abstraite devient plus facile à comprendre quand on l’applique à un ensemble d’événements régi par une loi de probabilité, car toute loi de probabilité a la propriété de définir une partition sur l’ensemble des événements (événements favorables, événements non favorables). Soit, par exemple, une urne contenant 2 boules blanches et 6 boules noires, et considérons l’expérience qui consiste à tirer une boule. La probabilité de tirer une boule blanche est 2/8 = 1/4. La probabilité de tirer une boule noire est 6/8 = 3/4. Il en résulte que l’apparition d’une boule blanche donnera une quantité d’information égale à log 4 = 2 logons, et que l’apparition d’une boule noire donnera une quantité d’information égale à lg(4/3) = 0,415 logon.Le raisonnement précédent ne permet d’évaluer la quantité d’information fournie par le tirage d’une boule que lorsque celui-ci a été effectué, c’est-à-dire que ce raisonnement a trait au résultat de l’expérience, et non à l’expérience elle-même. Pour évaluer a priori la quantité d’information moyenne que va fournir une expérience, il faut faire appel aux propriétés statistiques des résultats de l’expérience. Si l’on répète en effet un grand nombre de fois l’expérience précédente, on sait, par la loi des grands nombres, que l’on tirera en moyenne une boule blanche une fois sur quatre et une boule noire trois fois sur quatre. Dans ces conditions, la quantité d’information moyenne par expérience sera donnée par:
Cette notion assez abstraite devient plus facile à comprendre quand on l’applique à un ensemble d’événements régi par une loi de probabilité, car toute loi de probabilité a la propriété de définir une partition sur l’ensemble des événements (événements favorables, événements non favorables). Soit, par exemple, une urne contenant 2 boules blanches et 6 boules noires, et considérons l’expérience qui consiste à tirer une boule. La probabilité de tirer une boule blanche est 2/8 = 1/4. La probabilité de tirer une boule noire est 6/8 = 3/4. Il en résulte que l’apparition d’une boule blanche donnera une quantité d’information égale à log 4 = 2 logons, et que l’apparition d’une boule noire donnera une quantité d’information égale à lg(4/3) = 0,415 logon.Le raisonnement précédent ne permet d’évaluer la quantité d’information fournie par le tirage d’une boule que lorsque celui-ci a été effectué, c’est-à-dire que ce raisonnement a trait au résultat de l’expérience, et non à l’expérience elle-même. Pour évaluer a priori la quantité d’information moyenne que va fournir une expérience, il faut faire appel aux propriétés statistiques des résultats de l’expérience. Si l’on répète en effet un grand nombre de fois l’expérience précédente, on sait, par la loi des grands nombres, que l’on tirera en moyenne une boule blanche une fois sur quatre et une boule noire trois fois sur quatre. Dans ces conditions, la quantité d’information moyenne par expérience sera donnée par: ce qui représente l’entropie de la loi de probabilité telle qu’elle résulte de la définition donnée ci-dessus.3. Codage en l’absence de bruit Notion de codePour transmettre un message, il faut nécessairement le coder, le mode de codage dépendant de la nature du canal de transmission (l’écriture, la parole, le code Morse, etc., sont autant de modes de codage différents de l’information). On emploie plus souvent des codes binaires, c’est-à-dire des codes utilisant uniquement les symboles 0 et 1.Si l’on considère un alphabet S =s 1, s 2, ..., s k, dont les symboles sont les s i , et un alphabet X =x 1, x 2, ..., x q, dont les symboles sont les x i , un code est une application qui à toute suite de symbole de S (alphabet source) fait correspondre une suite de symboles de X (alphabet code).Un code-bloc est un code qui à tout symbole de S fait correspondre une séquence de symboles de X encore appelée mot code. Pour qu’un code soit utilisable, il faut qu’il soit non singulier (tous les mots codes doivent être distincts) et à décodage unique, c’est-à-dire non ambigu à la réception. Par exemple, le code s 10, s 210, s 300, s 401 n’est pas utilisable, car il n’est pas à décodage unique; en effet, le message 010100 peut être interprété de trois façons différentes:
ce qui représente l’entropie de la loi de probabilité telle qu’elle résulte de la définition donnée ci-dessus.3. Codage en l’absence de bruit Notion de codePour transmettre un message, il faut nécessairement le coder, le mode de codage dépendant de la nature du canal de transmission (l’écriture, la parole, le code Morse, etc., sont autant de modes de codage différents de l’information). On emploie plus souvent des codes binaires, c’est-à-dire des codes utilisant uniquement les symboles 0 et 1.Si l’on considère un alphabet S =s 1, s 2, ..., s k, dont les symboles sont les s i , et un alphabet X =x 1, x 2, ..., x q, dont les symboles sont les x i , un code est une application qui à toute suite de symbole de S (alphabet source) fait correspondre une suite de symboles de X (alphabet code).Un code-bloc est un code qui à tout symbole de S fait correspondre une séquence de symboles de X encore appelée mot code. Pour qu’un code soit utilisable, il faut qu’il soit non singulier (tous les mots codes doivent être distincts) et à décodage unique, c’est-à-dire non ambigu à la réception. Par exemple, le code s 10, s 210, s 300, s 401 n’est pas utilisable, car il n’est pas à décodage unique; en effet, le message 010100 peut être interprété de trois façons différentes: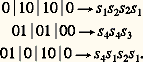 Longueur d’un codeSi S = (s 1, s 2, ..., s k ) est un alphabet source tel que p i soit la probabilité d’apparition du symbole s i et si s iXi est un code où Xi est un mot de longueur l i , alors la longueur moyenne du code est donnée par:
Longueur d’un codeSi S = (s 1, s 2, ..., s k ) est un alphabet source tel que p i soit la probabilité d’apparition du symbole s i et si s iXi est un code où Xi est un mot de longueur l i , alors la longueur moyenne du code est donnée par: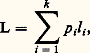 qui n’est autre chose que la somme pondérée des longueurs de tous les mots, et qui coïncide avec L , rapport entre le nombre de symboles binaires du message codé et le nombre de symboles du message source, lorsque le message est suffisamment long pour que tous les symboles sources apparaissent avec une fréquence relative égale à leur probabilité. On est dès lors conduit, pour minimiser la longueur d’un code, à attribuer les mots codes les plus courts aux symboles les plus fréquents; c’est ce que fit Morse de façon plus ou moins intuitive lorsqu’il créa le code qui porte son nom, et c’est aussi la méthode qu’utilisa Huffman, mais de façon plus systématique, lorsqu’il proposa sa méthode pour la recherche des codes de longueur minimale.Efficacité et redondance d’un codeConsidérons un alphabet source dont les symboles s 1 et s 2 ont respectivement les probabilités 0,8 et 0,2, et utilisons le code suivant:
qui n’est autre chose que la somme pondérée des longueurs de tous les mots, et qui coïncide avec L , rapport entre le nombre de symboles binaires du message codé et le nombre de symboles du message source, lorsque le message est suffisamment long pour que tous les symboles sources apparaissent avec une fréquence relative égale à leur probabilité. On est dès lors conduit, pour minimiser la longueur d’un code, à attribuer les mots codes les plus courts aux symboles les plus fréquents; c’est ce que fit Morse de façon plus ou moins intuitive lorsqu’il créa le code qui porte son nom, et c’est aussi la méthode qu’utilisa Huffman, mais de façon plus systématique, lorsqu’il proposa sa méthode pour la recherche des codes de longueur minimale.Efficacité et redondance d’un codeConsidérons un alphabet source dont les symboles s 1 et s 2 ont respectivement les probabilités 0,8 et 0,2, et utilisons le code suivant: L’entropie de la source est:
L’entropie de la source est: la longueur moyenne du code est: 0,8 憐 1 + 0,2 憐 1 = 1 symbole binaire par symbole.Dans ces conditions, on appelle efficacité:
la longueur moyenne du code est: 0,8 憐 1 + 0,2 憐 1 = 1 symbole binaire par symbole.Dans ces conditions, on appelle efficacité: en nombre de logons par symbole binaire, d’où l’on déduit la redondance r du code:
en nombre de logons par symbole binaire, d’où l’on déduit la redondance r du code: Pour l’exemple cité ci-dessus, on aura y = 0,723 logon par symbole binaire, soit une redondance de 27,7 p. 100, ce qui revient à dire que, tout en prenant le code le plus court possible, on gaspillera cependant 28 p. 100 du temps de transmission.Pour diminuer la redondance, on peut, au lieu de coder symbole par symbole, coder les messages de deux symboles successifs. On dit alors que l’on code l’extension d’ordre 2 de la source, et on aura:
Pour l’exemple cité ci-dessus, on aura y = 0,723 logon par symbole binaire, soit une redondance de 27,7 p. 100, ce qui revient à dire que, tout en prenant le code le plus court possible, on gaspillera cependant 28 p. 100 du temps de transmission.Pour diminuer la redondance, on peut, au lieu de coder symbole par symbole, coder les messages de deux symboles successifs. On dit alors que l’on code l’extension d’ordre 2 de la source, et on aura: ce qui donne pour l’entropie de la source:
ce qui donne pour l’entropie de la source: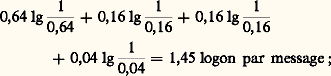 la longueur moyenne du code est 0,64 憐 1 + 0,16 憐 2 + 0,16 憐 3 + 0,04 憐 3 = 1,56 symbole binaire par message, ce qui implique une efficacité y = 1,45/1,56 = 0,93 logon par symbole binaire, soit une redondance de 7 p. 100 seulement au lieu de 28 p. 100, au prix malheureusement d’une complication des opérations de codage et de décodage. On montre, dans ces conditions, qu’en codant les symboles par groupes de n et en prenant n suffisamment grand, l’efficacité du codage peut devenir aussi voisine que l’on veut de sa limite supérieure, soit un logon par symbole binaire (premier théorème de Shannon).4. Codage en présence de bruitCanal binaireUn canal binaire est un canal à travers lequel on n’envoie que des signaux binaires (1 et 0, point et trait, etc.). Si le canal est imparfait (canal bruyant), la réception sera brouillée par le bruit, et la réception d’un 1 par exemple ne permettra pas de conclure à l’envoi d’un 1 en toute certitude, mais seulement avec une certaine probabilité.Un canal binaire symétrique (CBS) est un canal pour lequel la probabilité d’erreur est la même pour les deux symboles binaires. On appelle p cette probabilité, et on pose 樂 = 1 漣 p . Si l’on appelle distance de deux mots binaires le nombre de chiffres binaires par lesquels ils diffèrent, la probabilité de recevoir un mot de k symboles binaires, situé à une distance d du mot envoyé est 樂 ( k- d)pd . Pour un CBS de probabilité d’erreur 0,1, la probabilité de recevoir 10011 lorsqu’on envoie 11010 est 0,93 憐 0,12 = 0,739.Équivoque et transinformation d’un canalPour distinguer les symboles reçus des symboles envoyés, on appellera A =a 1, a 2, ..., a i , ..., a n les symboles envoyés, et B =b 1, b 2, ..., b j , ..., b n les symboles reçus. Les symboles de A ayant certaines probabilités, nous appellerons H(A) l’entropie de la source. L’observateur placé à l’extrémité réceptrice ne connaît pas H(A), mais peut s’en faire une idée, lorsqu’il reçoit b j , à l’aide des diverses probabilités p (a i /b j ) [probabilité que a i ait été émis lorsqu’il reçoit b j ], qu’il peut calculer à partir de p .Il peut donc évaluer H(A/b j ), c’est-à-dire l’entropie de la source vue de l’extrémité réceptrice lorsqu’il reçoit b j . Si l’on calcule la moyenne de H(A/b j ) étendue à tous les b j , l’on obtient H(A/B) qui est l’équivoque du canal due à son imperfection en ce sens que H(A/B) est nul pour un canal non bruyant.La différence I(A, B) = H(A) 漣 H(A/B), enfin, est appelée transinformation d’un canal et mesure en quelque sorte la quantité d’information effectivement transmise par un canal bruyant; elle est maximale et égale à H(A) lorsque l’équivoque est nulle, c’est-à-dire lorsqu’il n’y a pas de bruit.Capacité d’un canalLa transinformation d’un canal dépend de la loi de probabilité P(a i ), et cette quantité étant positive, il existe nécessairement une loi de probabilité P(a i ) qui maximise cette transinformation. On appelle capacité d’un canal ce maximum, et l’on voit dès lors que I(A,B) ne dépend plus de P(a i ), mais seulement du canal. Dans le cas du CBS, la capacité est donnée par C = 1 漣 H(p ) concernant les symboles binaires, et par Ck = k [1 漣 H(p )] pour des symboles codés par k symboles binaires.Vitesse de transmission d’un messageSi l’on considère une source qui envoie des 0 et des 1 de façon équiprobable à travers un CBS de probabilité d’erreur 0,01, l’entropie de la source est de un logon par symbole binaire, et la capacité du canal étant de 0,92, la quantité d’information reçue à l’extrémité de la ligne est de 0,92 logon par symbole binaire. Malheureusement, chaque logon est entaché d’erreur, et l’on ne sait toujours pas lorsqu’on reçoit un 1 si c’est 1 ou 0 qui a été envoyé, c’est-à-dire que l’on est incapable de reconstituer le message envoyé à partir du message reçu.Pour remédier à cet état de chose, on peut envoyer trois fois de suite le même symbole binaire, soit 111 pour 1 ou 000 pour 0.Dans ces conditions, on pourra recevoir une suite quelconque de trois signaux binaires à l’extrémité réceptrice, et l’on admettra que toute suite de trois signaux binaires figurant dans la colonne de gauche correspond à l’envoi d’un 0 et que toute suite figurant dans la colonne de droite correspond à l’envoi d’un 1:
la longueur moyenne du code est 0,64 憐 1 + 0,16 憐 2 + 0,16 憐 3 + 0,04 憐 3 = 1,56 symbole binaire par message, ce qui implique une efficacité y = 1,45/1,56 = 0,93 logon par symbole binaire, soit une redondance de 7 p. 100 seulement au lieu de 28 p. 100, au prix malheureusement d’une complication des opérations de codage et de décodage. On montre, dans ces conditions, qu’en codant les symboles par groupes de n et en prenant n suffisamment grand, l’efficacité du codage peut devenir aussi voisine que l’on veut de sa limite supérieure, soit un logon par symbole binaire (premier théorème de Shannon).4. Codage en présence de bruitCanal binaireUn canal binaire est un canal à travers lequel on n’envoie que des signaux binaires (1 et 0, point et trait, etc.). Si le canal est imparfait (canal bruyant), la réception sera brouillée par le bruit, et la réception d’un 1 par exemple ne permettra pas de conclure à l’envoi d’un 1 en toute certitude, mais seulement avec une certaine probabilité.Un canal binaire symétrique (CBS) est un canal pour lequel la probabilité d’erreur est la même pour les deux symboles binaires. On appelle p cette probabilité, et on pose 樂 = 1 漣 p . Si l’on appelle distance de deux mots binaires le nombre de chiffres binaires par lesquels ils diffèrent, la probabilité de recevoir un mot de k symboles binaires, situé à une distance d du mot envoyé est 樂 ( k- d)pd . Pour un CBS de probabilité d’erreur 0,1, la probabilité de recevoir 10011 lorsqu’on envoie 11010 est 0,93 憐 0,12 = 0,739.Équivoque et transinformation d’un canalPour distinguer les symboles reçus des symboles envoyés, on appellera A =a 1, a 2, ..., a i , ..., a n les symboles envoyés, et B =b 1, b 2, ..., b j , ..., b n les symboles reçus. Les symboles de A ayant certaines probabilités, nous appellerons H(A) l’entropie de la source. L’observateur placé à l’extrémité réceptrice ne connaît pas H(A), mais peut s’en faire une idée, lorsqu’il reçoit b j , à l’aide des diverses probabilités p (a i /b j ) [probabilité que a i ait été émis lorsqu’il reçoit b j ], qu’il peut calculer à partir de p .Il peut donc évaluer H(A/b j ), c’est-à-dire l’entropie de la source vue de l’extrémité réceptrice lorsqu’il reçoit b j . Si l’on calcule la moyenne de H(A/b j ) étendue à tous les b j , l’on obtient H(A/B) qui est l’équivoque du canal due à son imperfection en ce sens que H(A/B) est nul pour un canal non bruyant.La différence I(A, B) = H(A) 漣 H(A/B), enfin, est appelée transinformation d’un canal et mesure en quelque sorte la quantité d’information effectivement transmise par un canal bruyant; elle est maximale et égale à H(A) lorsque l’équivoque est nulle, c’est-à-dire lorsqu’il n’y a pas de bruit.Capacité d’un canalLa transinformation d’un canal dépend de la loi de probabilité P(a i ), et cette quantité étant positive, il existe nécessairement une loi de probabilité P(a i ) qui maximise cette transinformation. On appelle capacité d’un canal ce maximum, et l’on voit dès lors que I(A,B) ne dépend plus de P(a i ), mais seulement du canal. Dans le cas du CBS, la capacité est donnée par C = 1 漣 H(p ) concernant les symboles binaires, et par Ck = k [1 漣 H(p )] pour des symboles codés par k symboles binaires.Vitesse de transmission d’un messageSi l’on considère une source qui envoie des 0 et des 1 de façon équiprobable à travers un CBS de probabilité d’erreur 0,01, l’entropie de la source est de un logon par symbole binaire, et la capacité du canal étant de 0,92, la quantité d’information reçue à l’extrémité de la ligne est de 0,92 logon par symbole binaire. Malheureusement, chaque logon est entaché d’erreur, et l’on ne sait toujours pas lorsqu’on reçoit un 1 si c’est 1 ou 0 qui a été envoyé, c’est-à-dire que l’on est incapable de reconstituer le message envoyé à partir du message reçu.Pour remédier à cet état de chose, on peut envoyer trois fois de suite le même symbole binaire, soit 111 pour 1 ou 000 pour 0.Dans ces conditions, on pourra recevoir une suite quelconque de trois signaux binaires à l’extrémité réceptrice, et l’on admettra que toute suite de trois signaux binaires figurant dans la colonne de gauche correspond à l’envoi d’un 0 et que toute suite figurant dans la colonne de droite correspond à l’envoi d’un 1: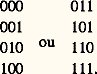 On néglige dans ce cas la probabilité d’avoir simultanément deux signaux ou trois signaux binaires erronés, soit 3 樂 2p + p 3 力 3 練 10-4 pour un canal ayant une probabilité d’erreur de 0,01. De façon plus générale, si pour chaque 1 à envoyer on envoie 2 n + 1 signaux 1 en décidant qu’à l’extrémité réceptrice toute suite comprenant un nombre de 1 supérieur à n + 1 correspond à l’envoi d’un 1, on réduit la probabilité d’erreur de reconstitution du message envoyé au fur et à mesure que l’on augmente n . On constate que la probabilité d’erreur décroît linéairement lorsque n croît, c’est-à-dire que la probabilité d’erreur tend vers zéro lorsque n tend vers l’infini.Si l’on appelle vitesse de transmission le quotient du nombre de symboles binaires transmis par le nombre de signaux binaires utilisés pour transmettre ces symboles binaires, on dira que la probabilité d’erreur dans la reconstitution du message envoyé tend vers 0 en même temps que la vitesse de transmission.Codage optimal en présence de bruitLe codage optimal en présence de bruit a été résolu par Shannon qui a démontré dans son deuxième théorème un résultat inattendu: il existe des codes conduisant à des vitesses de transmission aussi voisines que l’on veut de la capacité du canal et qui permettent de rendre la probabilité d’erreur de transmission inférieure à tout nombre donné à l’avance.Ce théorème n’indique malheureusement pas comment on peut trouver un tel code, et il n’a toujours pas été découvert; cela signifie qu’à l’heure actuelle, pour tous les codes connus, la vitesse de transmission se rapproche, plus ou moins lentement, de zéro en même temps que la probabilité d’erreur de transmission.5. L’idée d’information en biologieLa biologie moléculaire fait grand usage du vocabulaire de la théorie de l’information depuis l’introduction de la notion d’information génétique [cf. GÉNÉTIQUE]:– présence au sein des cellules de molécules codées ou «informationnelles» ADN et ARN;– transmission d’information par la voie ADNARN messager;– décodage permettant la synthèse (au niveau des ribosomes) des polypeptides nécessaires au métabolisme.Elle se garde pourtant d’en appliquer la formulation mathématique, car le caractère probabiliste que donne Shannon à la quantité d’information véhiculée ne tient pas compte de la signification du message. La nécessité, chez les Eucaryotes, d’un façonnage post-transcriptionnel des polypeptides montre que cette signification ne se dégage qu’en rapport avec le fonctionnement cellulaire tout entier. Celui-ci conditionne à son tour l’existence des agents intracellulaires de l’information selon un effet de circularité inhérent à l’organisation cellulaire elle-même [cf. GÉNÉTIQUE MOLÉCULAIRE].L’activation des unités codantes, les gènes, nécessite l’intervention des signaux qui déclenchent la régulation de l’expression du génome et permettent le déroulement vital, selon les normes que définit le programme génétique . Le développement de l’organisme découle ainsi de l’information génétique qu’il détient, mais avec une marge de manœuvre dite épigénétique, laissant un rôle modulateur au milieu dans lequel se déroule la vie.Au sein de l’organisme, chaque cellule devra donc obéir aux influences régulatrices et modulatrices, issues de l’organisme lui-même, qui permettront aux tissus de se différencier. La soumission aux contraintes du contexte biologique est liée à l’existence de récepteurs qui captent l’information organisatrice. Dans les cellules du corps humain, des récepteurs nucléaires répondent aux signaux que constituent les hormones stéroïdes, en agissant au niveau des gènes.D’autres récepteurs, membranaires, captent au-dehors des signaux très divers, notamment ceux du système nerveux ou ceux du système immunitaire, dont la transduction permettra (notamment par nucléotides cycliques interposés) l’adaptation fonctionnelle des cellules ainsi informées.La communication intercellulaire qui en résulte permet une coopération des tissus et une coordination de leurs fonctions. Au niveau global, l’acquisition d’information représente pour chaque organisme une contrainte biologique vitale, car elle conditionne toute adaptation. C’est pourquoi les procédures de communication, pour autant qu’elles aient une répercussion cognitive, ont une importance majeure dans l’ontogenèse comportementale.Ces faits apparaissent ainsi en rapport direct avec la marche de l’évolution.
On néglige dans ce cas la probabilité d’avoir simultanément deux signaux ou trois signaux binaires erronés, soit 3 樂 2p + p 3 力 3 練 10-4 pour un canal ayant une probabilité d’erreur de 0,01. De façon plus générale, si pour chaque 1 à envoyer on envoie 2 n + 1 signaux 1 en décidant qu’à l’extrémité réceptrice toute suite comprenant un nombre de 1 supérieur à n + 1 correspond à l’envoi d’un 1, on réduit la probabilité d’erreur de reconstitution du message envoyé au fur et à mesure que l’on augmente n . On constate que la probabilité d’erreur décroît linéairement lorsque n croît, c’est-à-dire que la probabilité d’erreur tend vers zéro lorsque n tend vers l’infini.Si l’on appelle vitesse de transmission le quotient du nombre de symboles binaires transmis par le nombre de signaux binaires utilisés pour transmettre ces symboles binaires, on dira que la probabilité d’erreur dans la reconstitution du message envoyé tend vers 0 en même temps que la vitesse de transmission.Codage optimal en présence de bruitLe codage optimal en présence de bruit a été résolu par Shannon qui a démontré dans son deuxième théorème un résultat inattendu: il existe des codes conduisant à des vitesses de transmission aussi voisines que l’on veut de la capacité du canal et qui permettent de rendre la probabilité d’erreur de transmission inférieure à tout nombre donné à l’avance.Ce théorème n’indique malheureusement pas comment on peut trouver un tel code, et il n’a toujours pas été découvert; cela signifie qu’à l’heure actuelle, pour tous les codes connus, la vitesse de transmission se rapproche, plus ou moins lentement, de zéro en même temps que la probabilité d’erreur de transmission.5. L’idée d’information en biologieLa biologie moléculaire fait grand usage du vocabulaire de la théorie de l’information depuis l’introduction de la notion d’information génétique [cf. GÉNÉTIQUE]:– présence au sein des cellules de molécules codées ou «informationnelles» ADN et ARN;– transmission d’information par la voie ADNARN messager;– décodage permettant la synthèse (au niveau des ribosomes) des polypeptides nécessaires au métabolisme.Elle se garde pourtant d’en appliquer la formulation mathématique, car le caractère probabiliste que donne Shannon à la quantité d’information véhiculée ne tient pas compte de la signification du message. La nécessité, chez les Eucaryotes, d’un façonnage post-transcriptionnel des polypeptides montre que cette signification ne se dégage qu’en rapport avec le fonctionnement cellulaire tout entier. Celui-ci conditionne à son tour l’existence des agents intracellulaires de l’information selon un effet de circularité inhérent à l’organisation cellulaire elle-même [cf. GÉNÉTIQUE MOLÉCULAIRE].L’activation des unités codantes, les gènes, nécessite l’intervention des signaux qui déclenchent la régulation de l’expression du génome et permettent le déroulement vital, selon les normes que définit le programme génétique . Le développement de l’organisme découle ainsi de l’information génétique qu’il détient, mais avec une marge de manœuvre dite épigénétique, laissant un rôle modulateur au milieu dans lequel se déroule la vie.Au sein de l’organisme, chaque cellule devra donc obéir aux influences régulatrices et modulatrices, issues de l’organisme lui-même, qui permettront aux tissus de se différencier. La soumission aux contraintes du contexte biologique est liée à l’existence de récepteurs qui captent l’information organisatrice. Dans les cellules du corps humain, des récepteurs nucléaires répondent aux signaux que constituent les hormones stéroïdes, en agissant au niveau des gènes.D’autres récepteurs, membranaires, captent au-dehors des signaux très divers, notamment ceux du système nerveux ou ceux du système immunitaire, dont la transduction permettra (notamment par nucléotides cycliques interposés) l’adaptation fonctionnelle des cellules ainsi informées.La communication intercellulaire qui en résulte permet une coopération des tissus et une coordination de leurs fonctions. Au niveau global, l’acquisition d’information représente pour chaque organisme une contrainte biologique vitale, car elle conditionne toute adaptation. C’est pourquoi les procédures de communication, pour autant qu’elles aient une répercussion cognitive, ont une importance majeure dans l’ontogenèse comportementale.Ces faits apparaissent ainsi en rapport direct avec la marche de l’évolution.
Encyclopédie Universelle. 2012.